ソース:
訳:
Burp Spider
私たちが試してみる最後のクローラーは、Burp Spider で。
これが今のところ私のお気に入りですが、効率的にするにはかなり優れたコンピュータが必要で。
残念ながら、私のコンピューターはかなり古いものですが、単純なクロールであればほぼ問題ないと。
その前に、スコープを設定する必要があります。
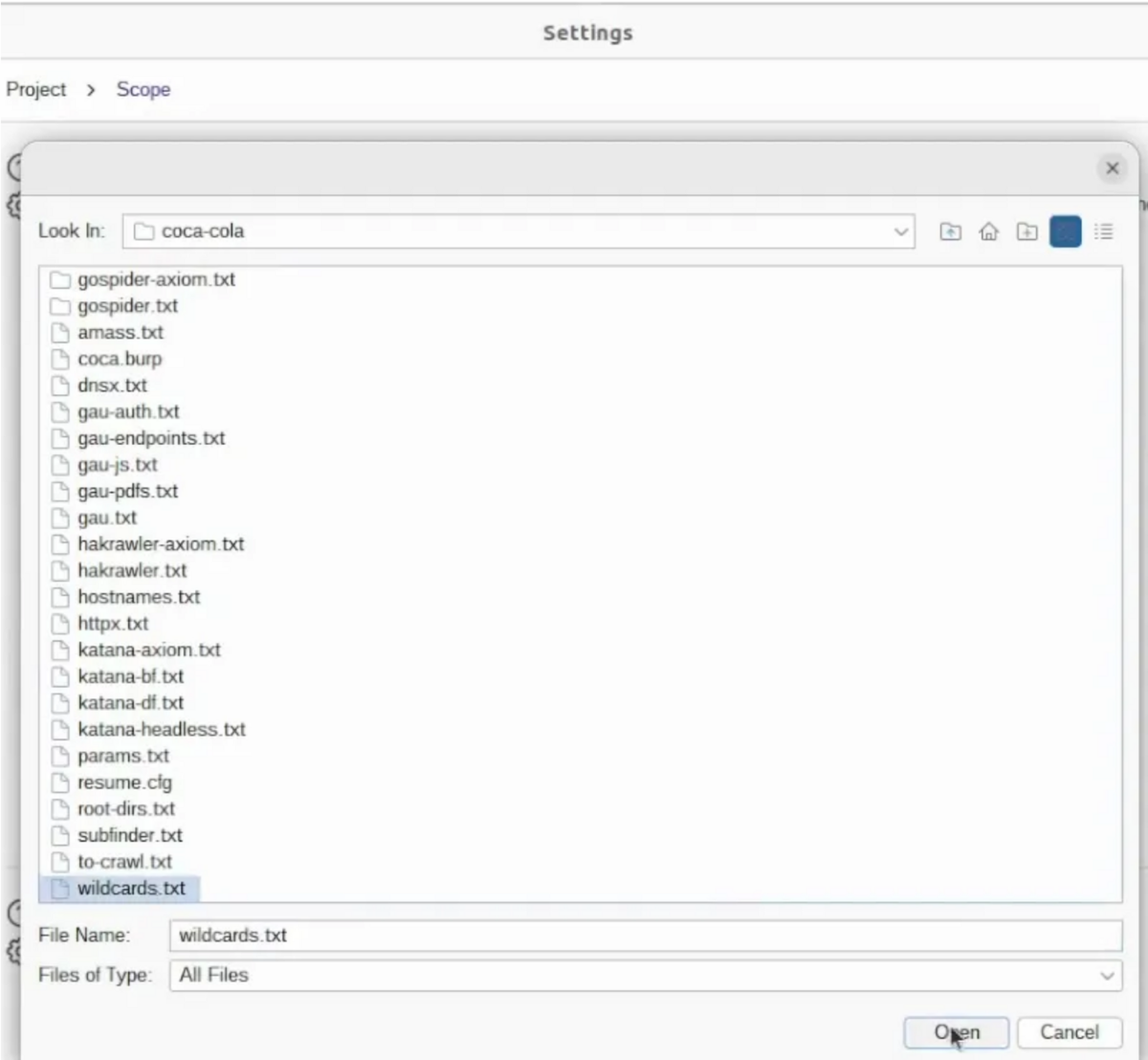
ターゲット -> スコープ設定に移動し、高度なコントロールを使用すると、「ロード」を使用してワイルドカードをロードしてみることができ。
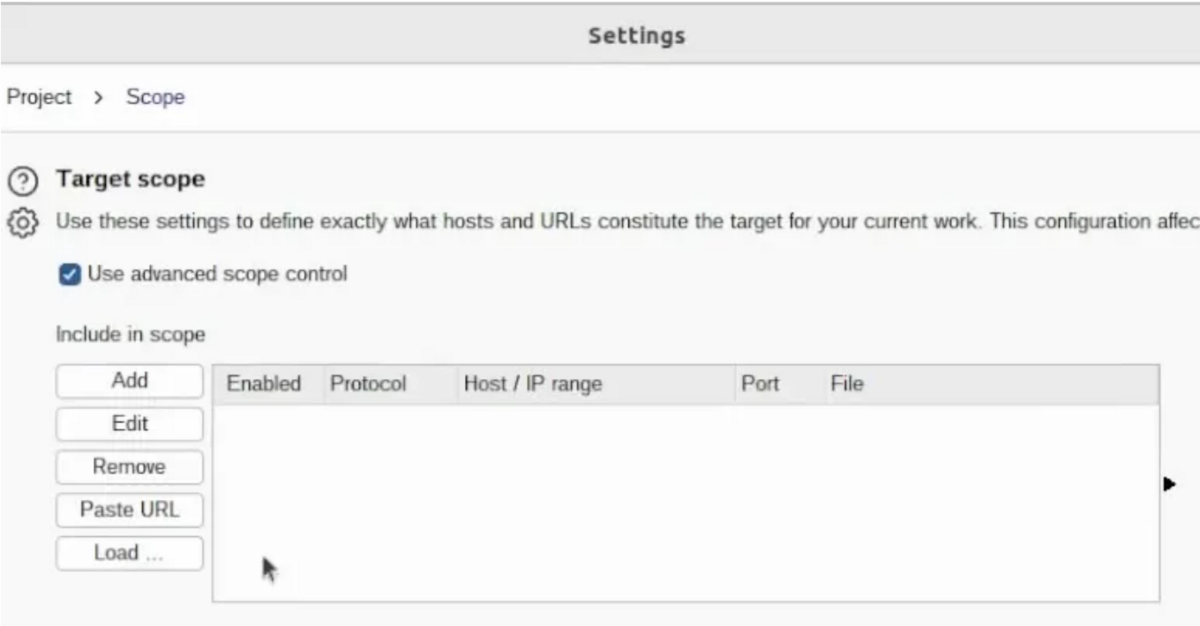
を追加することをお勧めします。 wildcards.txt これには
に移動します 次に、ダッシュボード -> 新しいスキャン -> クロール 。
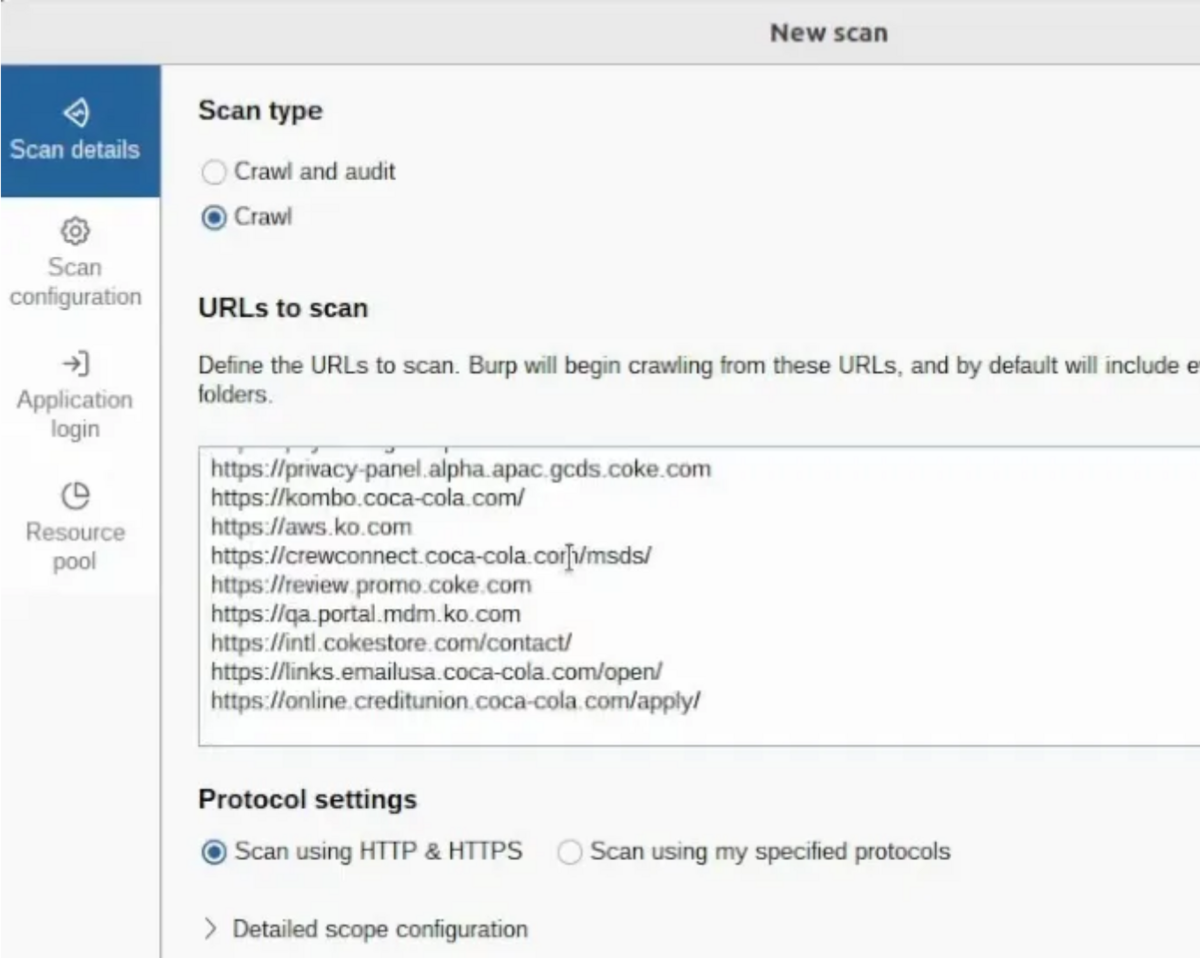
URLを読み込んでスキャンしたいと考えて。
ファイルをcat して to-crawl.txt 、 xclip ユーティリティを選択してコピーしてみます。
cat to-crawl.txt | xclip -selection copy
200 個の URL の場合は、ほぼ問題ありません。
セクションに貼り付けます これを「スキャンする URL」 。
ここでスキャン構成を編集してみて。

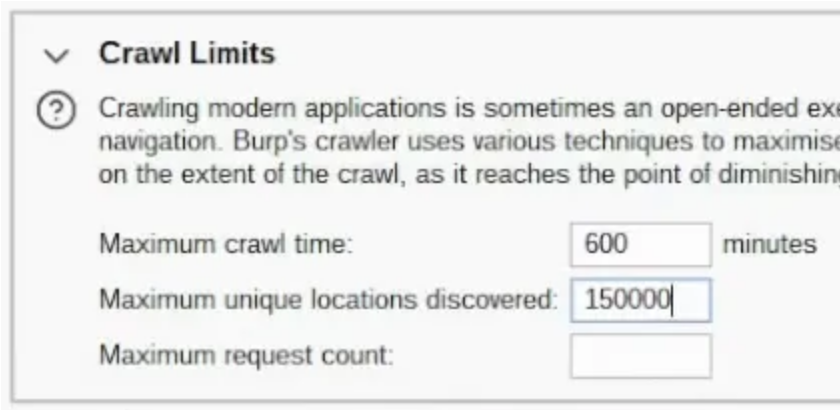
という名前を付け この設定にCrawler 、5 つのリンクの深さを使用し、いくつかの制限を設定する必要があります。

最大クロール期間は 600 分 にしたいです。 で発見されたユニークな場所 そして、 150000 :
他の設定はデフォルトのままにし、保存して実行してみて。
クローラーの実行が終了したら、結果をエクスポートしたいと思い。
収集したエンドポイントをエクスポートする方法には巧妙なトリックがあり。
GAP 拡張機能 を使用できます。 をインストールする必要があり Python とjython 、リンクする必要もあり。
タブに移動し[ターゲット] 、収集されたエンドポイントをすべて選択してGAP に送信。
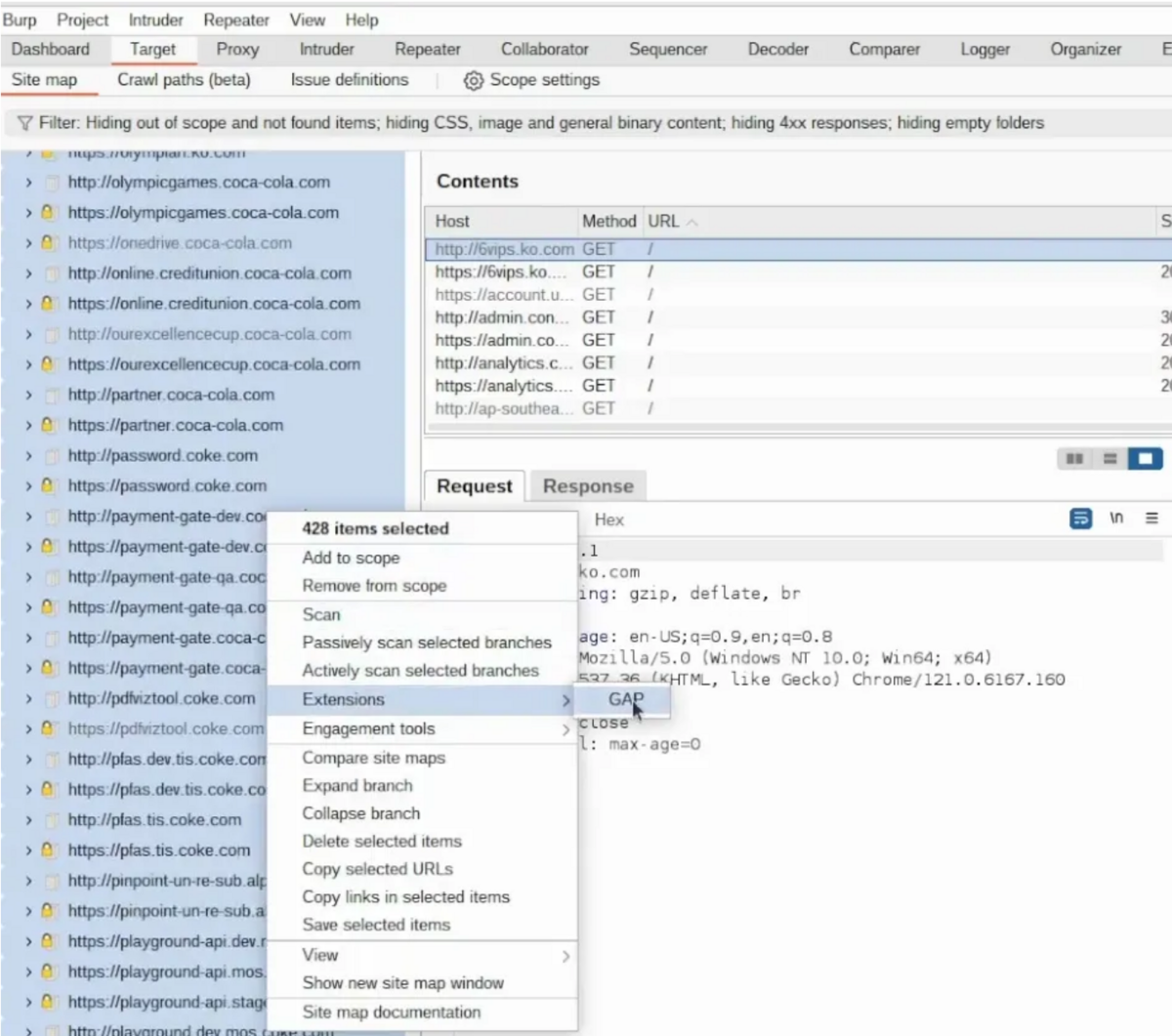
ロードされるまで待つ必要があり。
リンクのみが必要なものを選択し、それが完全にロードされるのを待って、「 範囲内のみ」 でフィルタリングし。
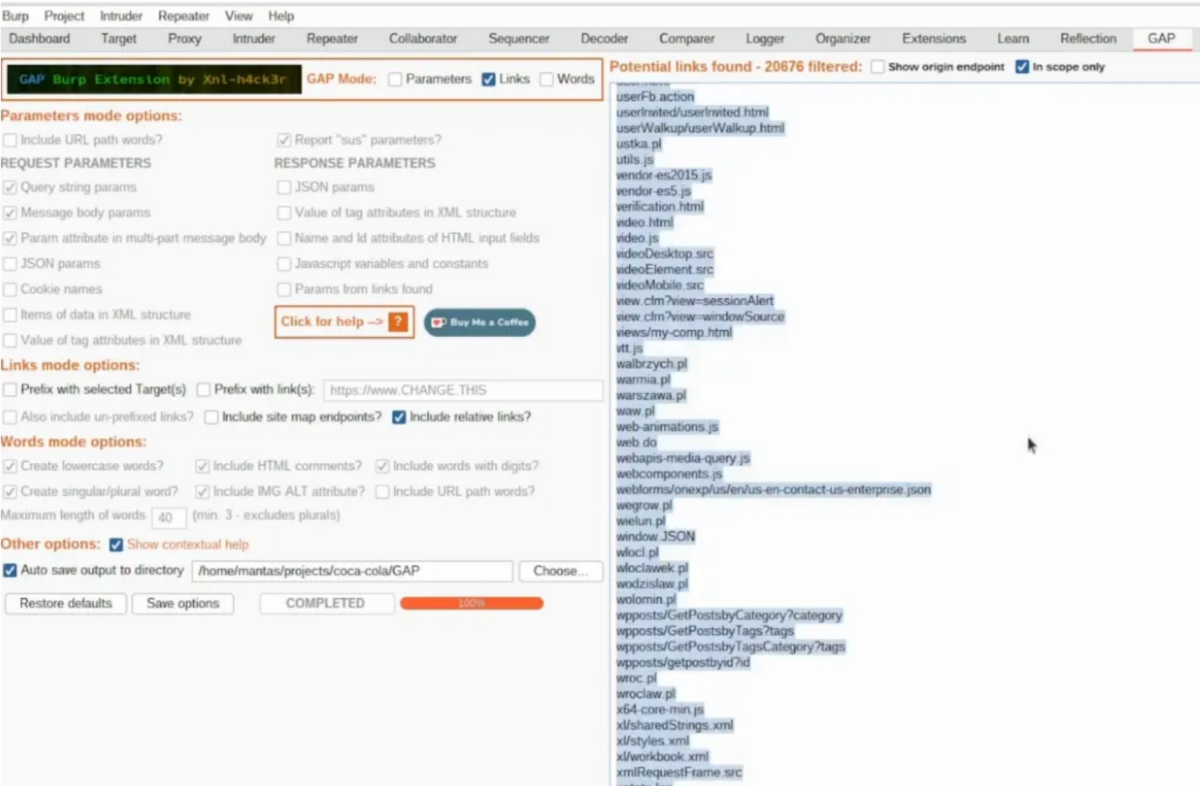
ジャンクな結果がたくさんあるため、 https を持つ結果のみを含めることをお勧めして。
Ctrl+C を押して、それらを gap.txt に配置し。
Burpを扱うときにお勧めします。
最良の方法は、[ターゲット] タブにアクセスして結果を表示し、他のサードパーティ ツールを使用しないことです…追加のチェックに合格したくない場合は除きます。
それはかなり良いアイデアかもしれませんが、この場合は、手動でテストし、バックグラウンドで実行するクローラーを使用しているときにのみBurp を使用し。